Georeactor Blog
RSS FeedSemantic search and GPT NYC
In 2021, I fine-tuned a GPT-2 model on /r/AskNYC questions and answers.
Assessing ChatGPT's answers to my original evaluation questions
Before working on the model, I picked a few questions which would be reasonable for a language model to answer. Here's how ChatGPT responded to them recently - I'd say that aside from small details, it's pretty much on the mark.
With ChatGPT performing so well, it's not clear if we still need an NYC-specific model. But sometimes people want a human answer:
![Redditor asks a simple question, says they feel more comfortable getting feedback from a real life experience [person]. Someone responds: but we are all bots here.](/blog-images/semanticsearch-1.png)
The rethink
ML projects increasingly use neural networks totally differently - when receiving a question, we could convert it to an embedding vector and search for the most similar question (and best answer) in our dataset.
When discussing a potential search engine with coworkers, I explained that the easiest searches are direct text match, followed by indexing techniques, and now semantic search ought to match even completely differently worded sentences with similar meaning.
Where to get sentence embeddings?
GPT-NYC converts words into tokens, and each token into a vector with 1,024 dimensions. Storing and comparing these word vectors is old news (word2vec). But how do we convert sentences into comparable vectors?
Old school methods for combining or averaging embeddings do worse on varying-length sentences, or sentences where word order matters.
SGPT is a new (2022) project for getting sentence embeddings out of GPT models.
OpenAI and Cohere offer APIs for embeddings from their LLMs. Both return 4,096-dimensional vectors. You benefit from the overall model training and size, though no fine-tuning.
Note that wherever we get embeddings, we need continual access to convert users' queries into embeddings.
Community consensus in January 2022 was that OpenAI's embeddings APIs underperformed and cost too much, but OpenAI worked on this and has cut prices a few times. For a production project we would need to consider all of the options, but I plan to use Cohere's free trial.
Searchable embeddings databases
Once we have vectors, where can we store and search them?
A recent post from Supabase on Hacker News discussed PostgreSQL's new support for the vector embedding type.
Pinecone is a purpose-built vector database-as-a-service.
Both offer a free tier.
Process
A script gets Cohere embeddings for each question and the first sentence (until first punctuation) of the extended self-text. There is some rate-limiting here, but luckily I have only ~600 questions.
I upsert the questions and embeddings to a Pinecone database. I use the unique part of the Reddit link as the ID, and add question in metadata, so when I search vectors, I can refer back to the original content.
From CoLab, I tested the Python -> Cohere API -> Pinecone query to return the original item.
Search UI
I decided to make a HuggingFace / Gradio Space with a single query going to Cohere and Pinecone before returning relevant links:
https://huggingface.co/spaces/georeactor/asknyc-vectorsearch
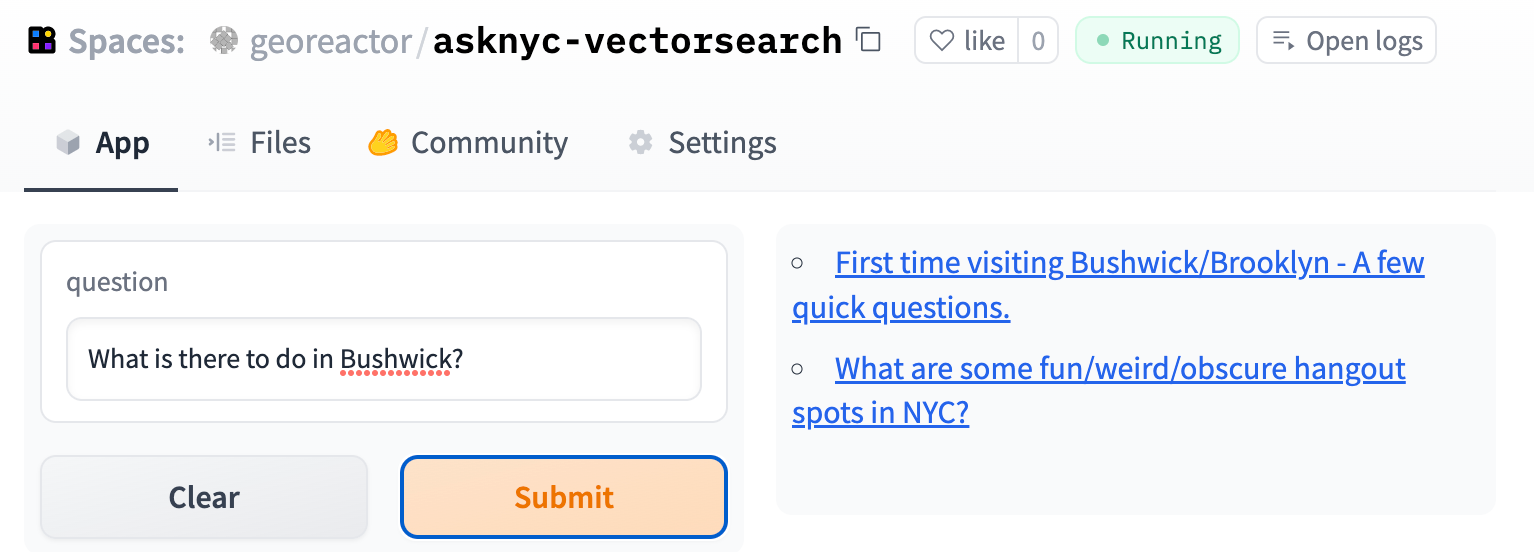
To be honest I didn't find these super-laser-accurate, and some questions have no answers on the subreddit. In other cases, it was annoying that I had put the body of the question into the embedding and not into the result. In the example below, both of these are actually decent references for someone who just graduated high school, but it's not clear.
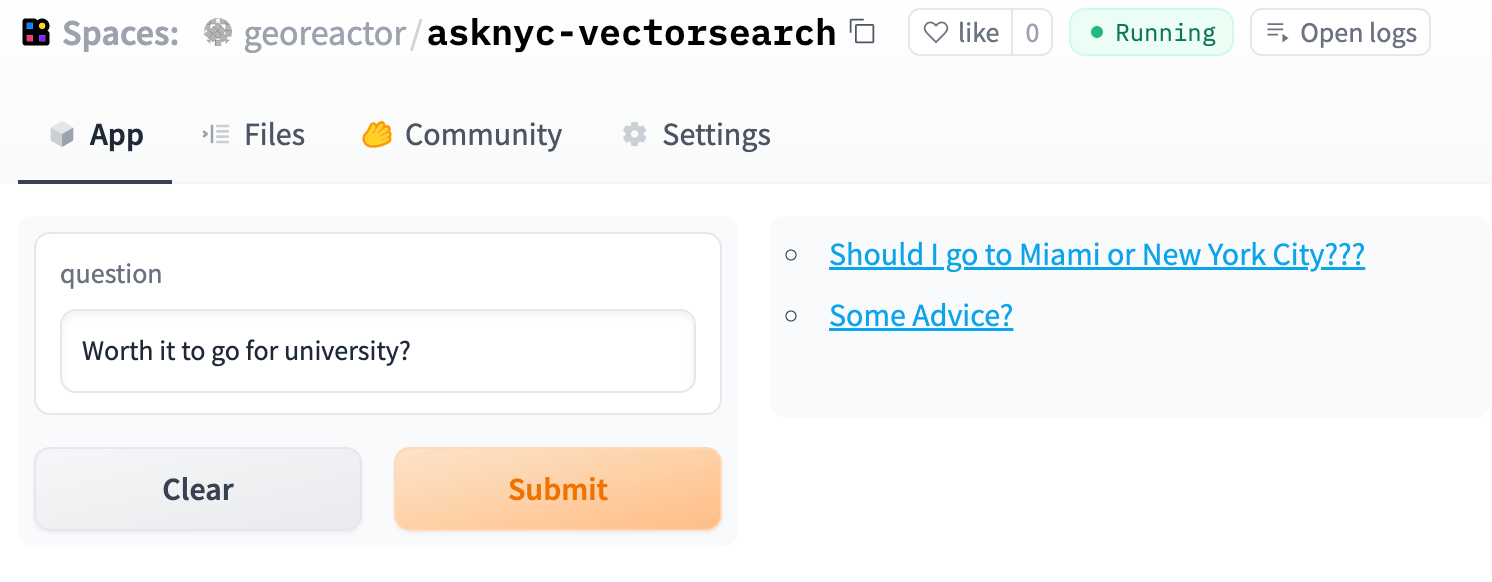
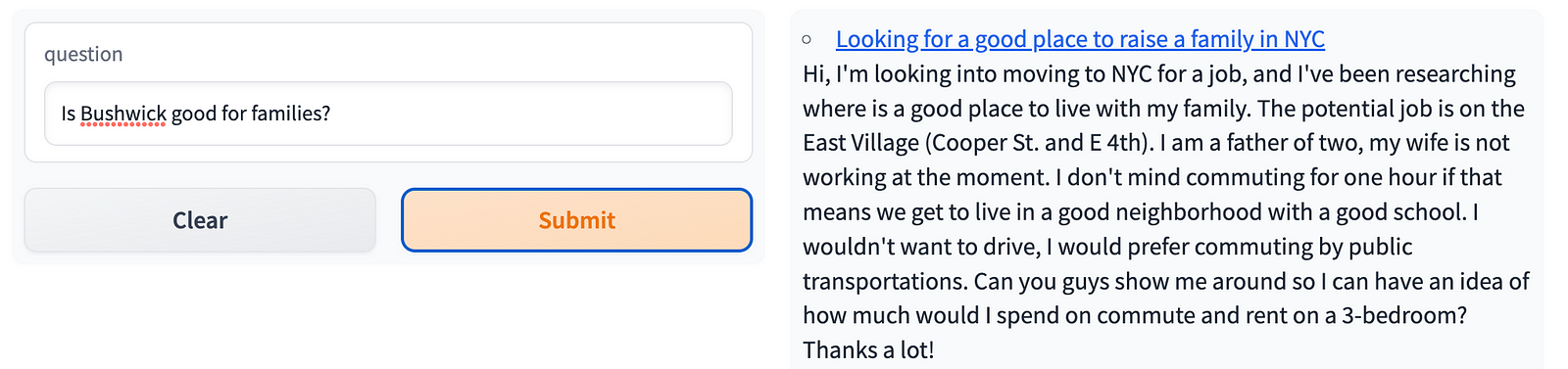
I re-ran my script with the upsert so I could include the body in the metadata.
Future Routes
I could use the SGPT project to create sentence embeddings based on fine-tuned GPT-NYC, but 1,024 dimensions is probably not comparable to Cohere/OpenAI.
My initial /r/AskNYC questions dataset comes from only five months between 2015 and 2019; this could be improved.
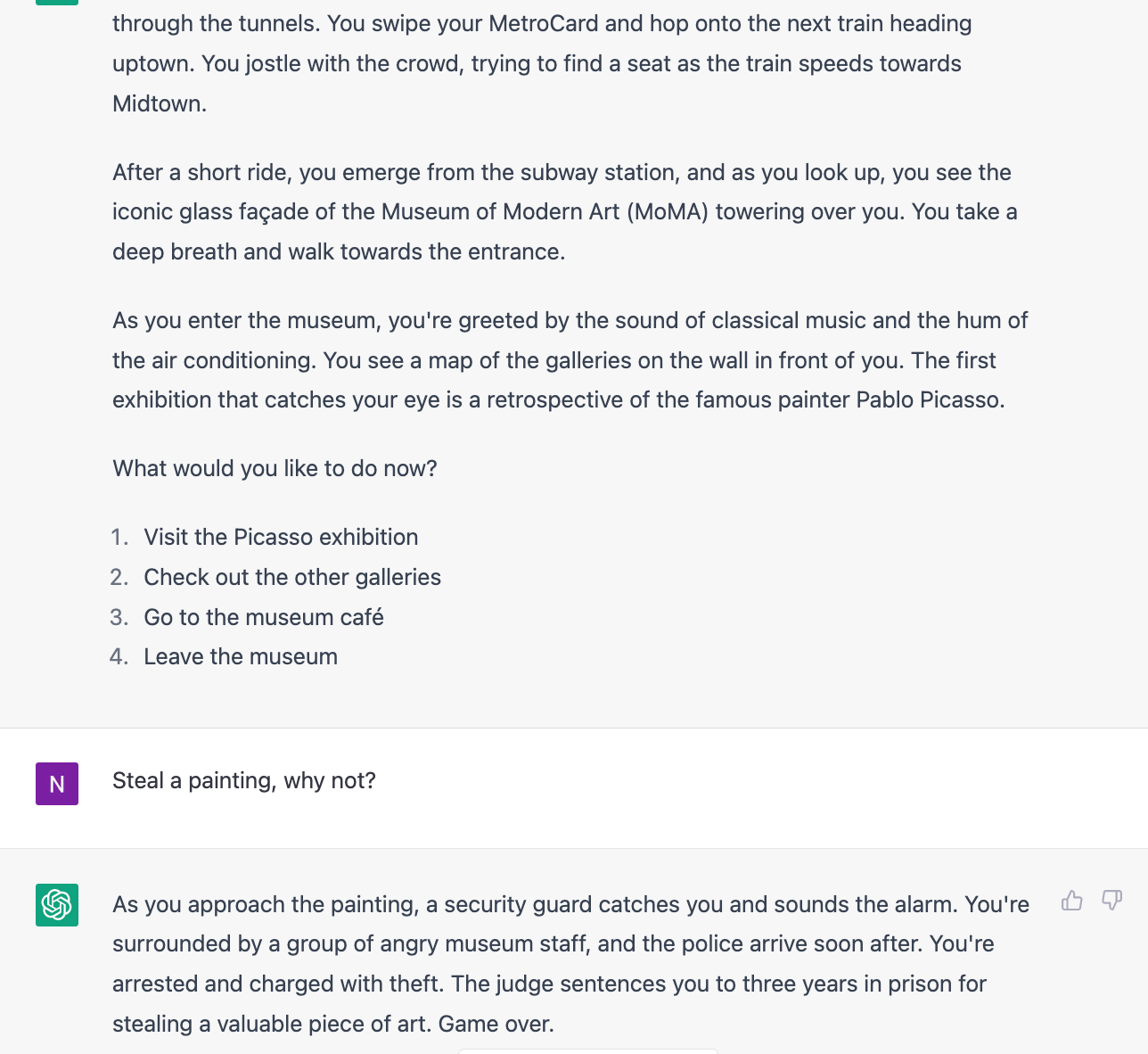
Prompt engineering to make ChatGPT role-play as a New Yorker (here's my adaptation from a Breaking Bad game).

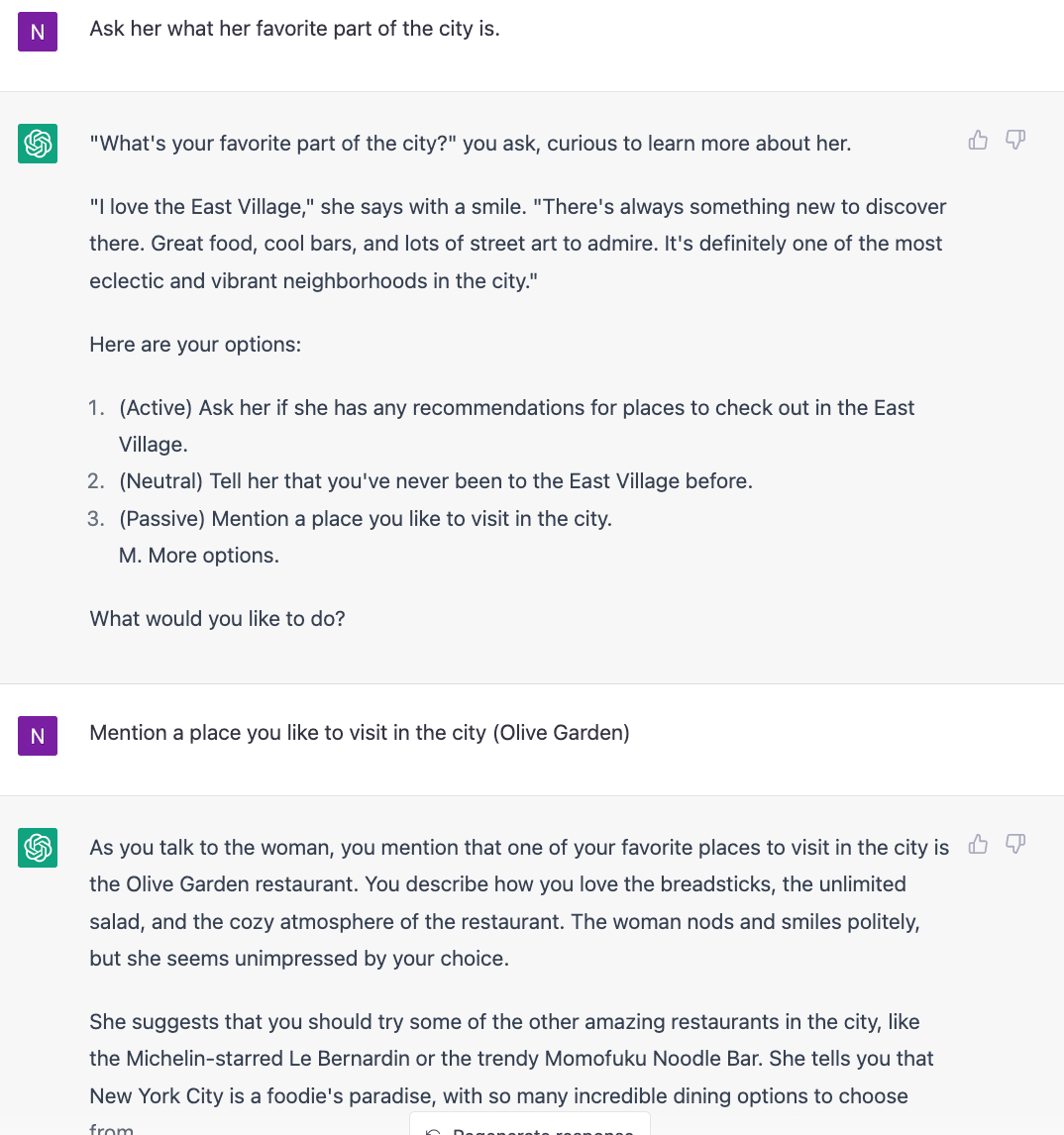
Previous research indicates that my NYC-specific vocabulary was more show than science (GPT-NYC favored this vocabulary in responses, over-represented some names which were rare in the fine-tuning dataset, and didn't have existing knowledge of these tokens encoded in GPT).
As mentioned in the original post, there are other question-friendly travel subreddits (/r/HawaiiVisitors and /r/JapanTravel) which could use the same tools.