Georeactor Blog
RSS FeedCartoon ML - Part 1 - BLIP
In September 2022, a fun new AI / ML task appeared: understanding of New Yorker cartoons (human opinions differ on whether these cartoons are humorous). They're available as a HuggingFace dataset with human-written descriptions, explanations, and finalist captions. The paper introduces a few tasks on the dataset, such as predicting which of the three captions was picked as the best.
I've been wanting to do several mini-projects with the dataset, the first being investigating image-to-text. Could an AI generate its own descriptions? Or enhance the human description to add information?
Preliminary notes on joke-generation in ChatGPT
ChatGPT can generate some jokes. It's a little tricky because you want to avoid repeating jokes from the internet corpus.
Here I tried to prod it into generating programming jokes of increasing difficulty, but instead it was revisiting the same joke with more off-kilter answers.
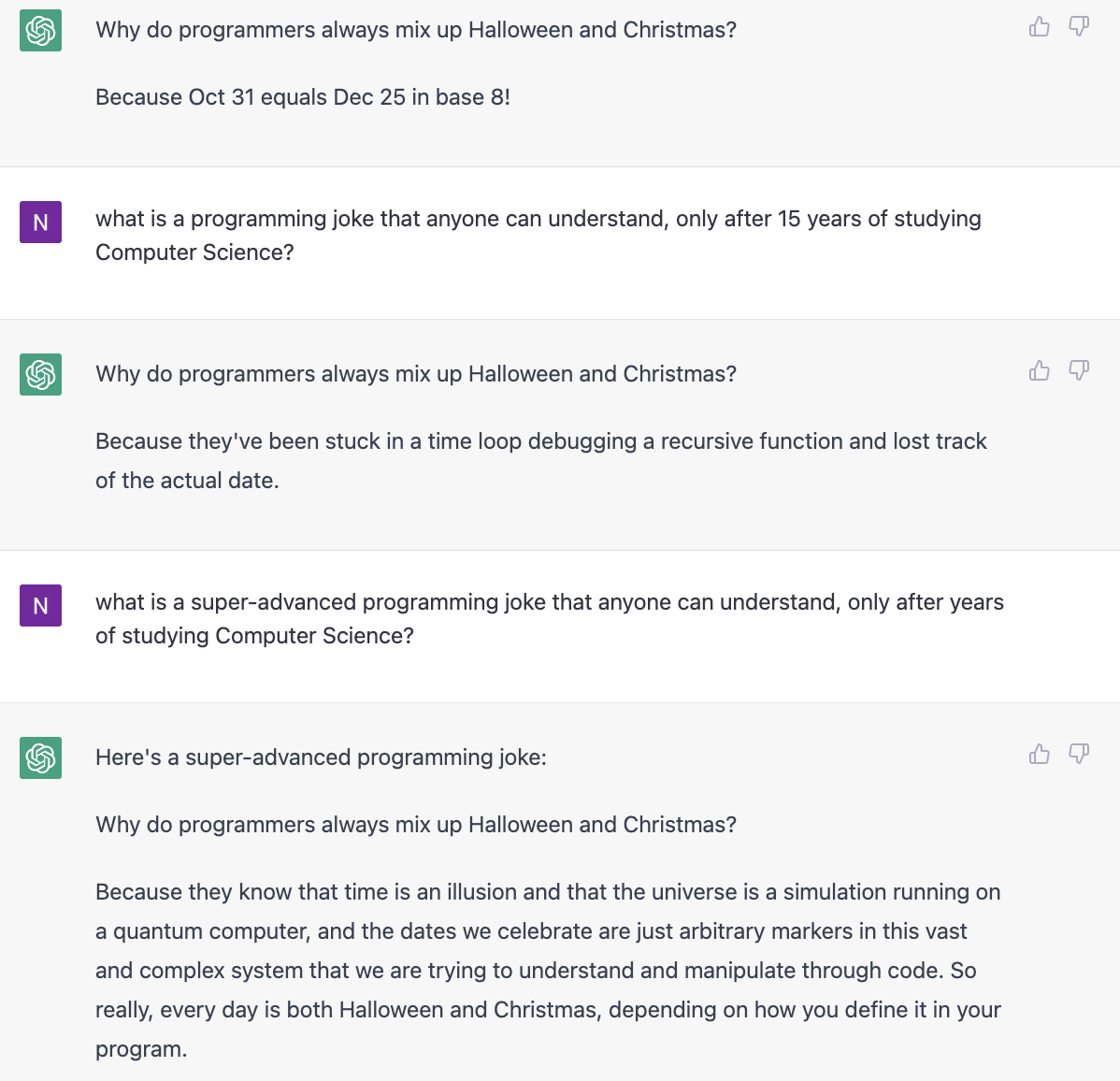
I also saw a blog post ChatGPT has trouble giving an answer before explaining its reasoning - which makes sense from an RLHF perspective - but could be antithetical to joke-generation? Only a few jokes work as a chain of thought / reasoned answer.
Getting to know BLIP-2
My first thought was to use Stable Diffusion. After some research on this, what I ought to say is using OpenAI's CLIP or Salesforce's BLIP. This is the component of the diffusion model stack which in one direction captions an image, and in the other direction measures how accurately its image matches the input prompt.
The BLIP-2 paper describes this as "a new vision-language pre-training method" rather than a specific model. When you pick out a model with BLIP-2, it builds on existing image and text models and you'll usually see that in the name (example: pretrain_opt2.7b).
Starting with an image

Caption: It seems like we're unable to lure them back to the office with free snacks. (Aug. 2021)
The first app which I tried, CLIP Interrogator, suggested this description for my first image:
a couple of people standing in a maze, a cartoon by Roz Chast, pexels, institutional critique, furaffinity, academic art, ray tracing
Roz Chast has published hundreds of New Yorker cartoons, so this seems to identify the style. Pexels is a stock photo library. I was encouraged by 'institutional critique' but then saw 'furaffinity'
We could maybe reverse-engineer from the tags that it is a cartoon with animals and a maze, but it's not sufficient information to replicate the cartoon. How can this be improved?
When I later re-ran the image on HuggingFace Spaces, after going through some JPEG compression, the description lengthened and improved slightly:
a cartoon drawing of a man and a woman in a maze, a cartoon, by Roz Chast, institutional critique, medical laboratory, enterprise workflow engine, missing panels, hamsters, metzinger, new yorker cartoon, loosely cropped, on a advanced lab, fair, helpful
Sylvain Filoni's CLIP Interrogator 2.1 suggested:
a cartoon drawing of a man and a woman in a maze, by Warren Mahy, in a lab, location in a apartment, new yorker illustration, mini model
This version recognizes the New Yorker cartoon and some aspects of the maze, lab, and mini apartment. The Warren Mahy reference is way off (he makes colorful fantasy concept art).
Using the BLIP-2 space, I get:
a cartoon drawing of two people looking at a maze
This is the first to correctly see the people looking at rather than being inside a maze.
Visual QA
My next idea was that captioning might not cover all of the info that a text model needs to understand the joke. What if we used Visual QA models to get information about any unusual characters and objects in the image?

Automated captions did not tell us before that the people are scientists, but now we have that.
Unfortunately it did not give us a lot of other information.
LAVIS
With the difficulty of getting a consistent read of my one image, it would be best if I started working with the full dataset and piped it directly into models. Salesforce's LAVIS is the library for working with their various tasks and text + vision models.
I created a CoLab notebook to try out their basic captioning example (which works on free CoLab + CPU).
The BLIP-2 models based on T5 and OPT are too large for the standard CoLab notebook RAM. I eventually went with blip2/coco. I also got to try out a Visual QA model.
Some notes
CLIP-Interrogator and BLIP UIs (on HuggingFace, Replicate, and elsewhere) are moving targets. Especially when they're popular, the developer will upgrade to newer models and match what people are searching (i.e. Stable Diffusion v2) rather than giving a distinct UI and specifying what's CLIP, BLIP v1, BLIP v2, etc.
When I take a screenshot of an image, download it from somewhere, upload it into a service, etc. it looks like the same image but it changes the dimensions and pixels enough to cause new issues.
Captioning models and scripts are getting better at concise, accurate captions. But I liked the longer noisier captions for this task - they included some good phrases ("medical laboratory", "new yorker cartoon").
Future Ideas
- Pick captions from the full dataset
- After fine-tuning a text model on the joke explanations, I'd like an "anti-explanation model" to attempt to justify mismatched captions.
- Use the official TorchMultimodal https://github.com/facebookresearch/multimodal
- Generate new captions
- Evaluate the three supposed 'universal New Yorker captions', and generate new ones.