Georeactor Blog
RSS FeedWork on Jais and mGPT
More quantized models, and evaluating Indonesian
A Quantized Arabic LLM
A few days ago, Inception and the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) announced a new bilingual English + Arabic LLM: jais-13b.
I was able to download and quantize this on CoLab Pro + an A100. The parameter count is about GPT-3.0, but comparison is complicated by the two languages. I'm hesitant to share the quantized weights, because Jais has a license step before access, and my change to those weights was minimal. I did create a public right-to-left CSS Gradio for people to try out the quantized model.
Running the model requires trusting Python execution, I assume for the custom tokenizer and activation function? Can I check that it's all working in the quantized version?
Here are some text completions in English and Arabic:
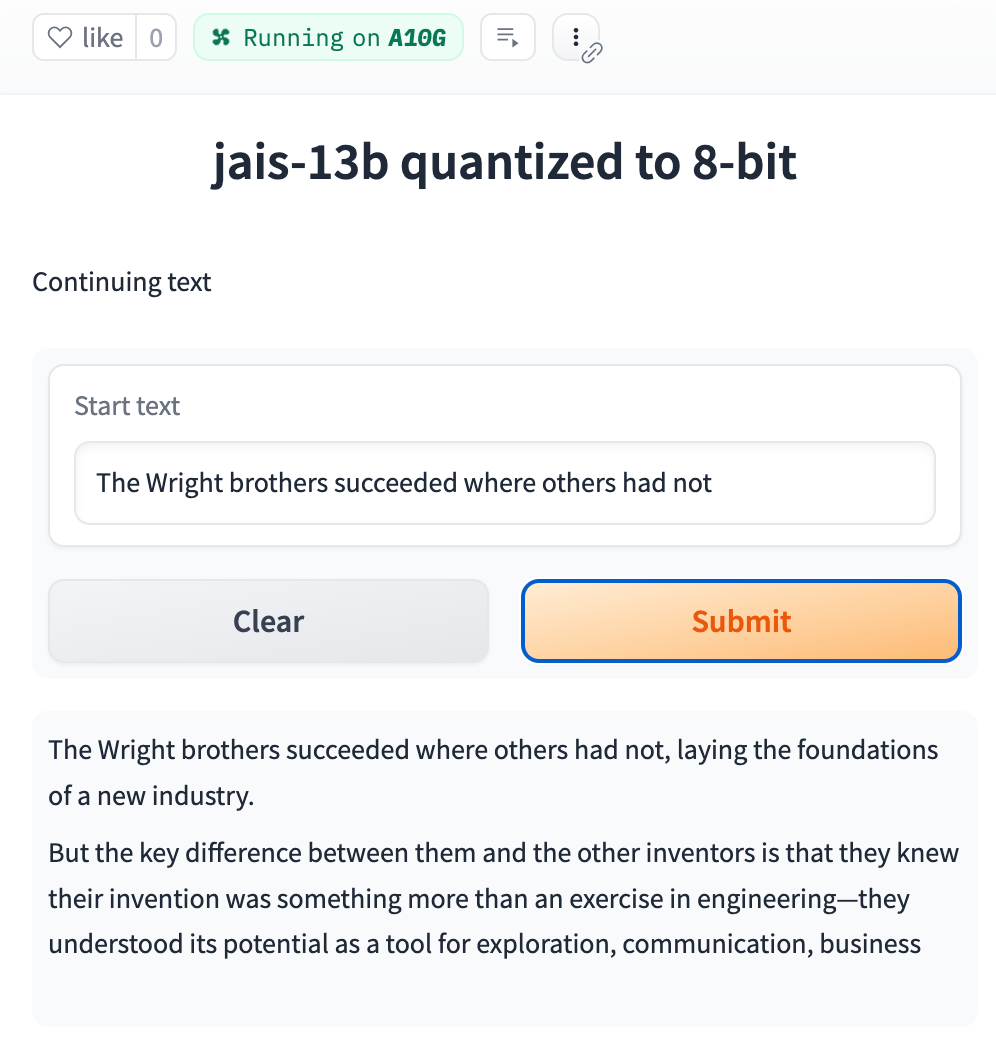
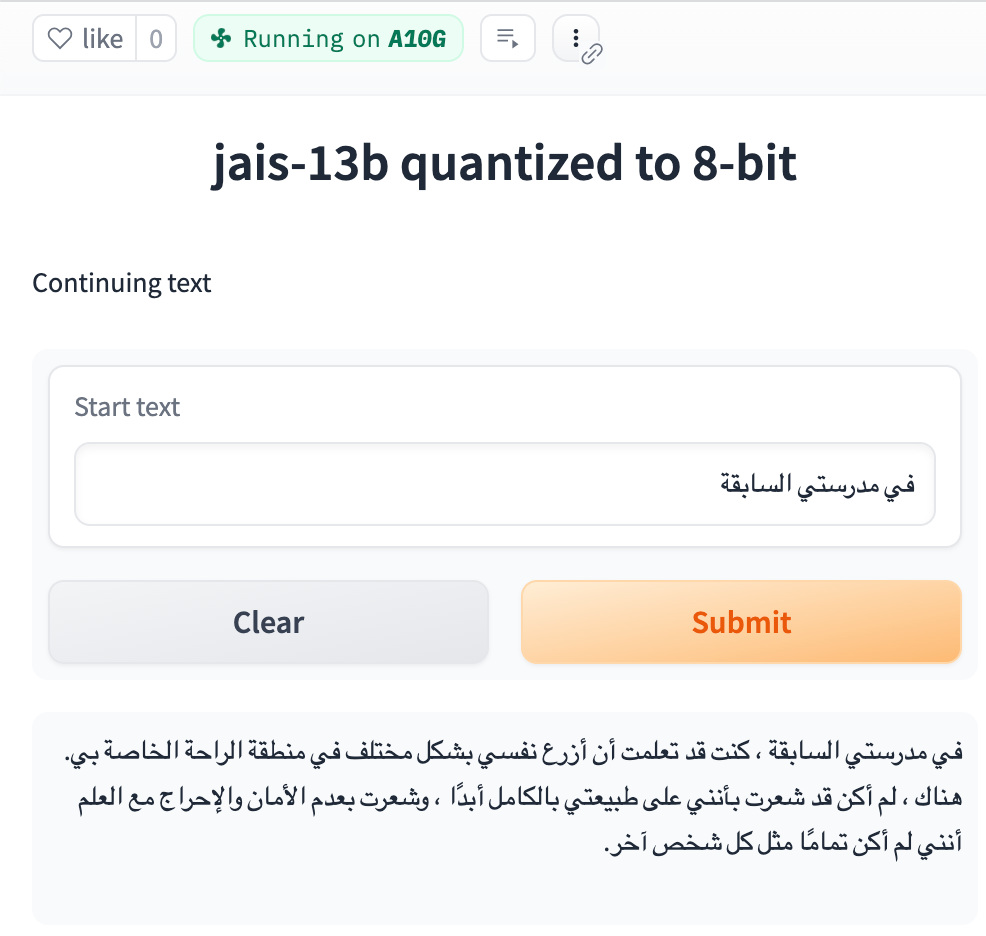
The Arabic prompt translated: At my previous school [...] (think Magic School Bus).
I also signed up to access the team's hosted chat models on https://arabic-gpt.ai
A Quantized mGPT-13B
Now, did this Jais-13B project mean that I could go back to my mGPT project and quantize their 13B model? It's close in file size, but it was taking a long time to download the weights. HuggingFace may do some CDN magic which benefits newer and more popular models, and throttles repeat downloads. I cloned the model to my laptop, updated my one-person Google Workspace for more storage, and waited for this to upload to Google Drive. With that, I can more quickly copy it into CoLab, do quantization on an A100, move the quantized weights back to Google Drive, and redistribute it on HuggingFace: https://huggingface.co/monsoon-nlp/mGPT-13B-quantized
Previously I talked about evaluating mGPT for Arabic, but now that there's Jais, the mGPT-13B model is something which I'd like to reserve to test on Hindi, Bahasa Indonesia, and maybe a few other languages which lack LLMs at this scale.
Evaluation on Indonesian
I went back to the EleutherAI eval harness. We ended up closing my PR to add the New Yorker cartoon contest text task (in part because I didn't demonstrate replication of the paper, in part because the paper appears to use the "uncanny description" which IMO gives away too much).
If I end up adding language benchmarks to the harness as planned, I'll pay more attention from the start toward replicating the paper.
From the built-in tasks, the two Hindi-specific ones are xnli_hi and xstory_cloze_hi, and Indonesian has xcopa_id and xstory_cloze_id. As subsets of large multilingual benchmarks, these could have serious quality issues, but we'll continue on for now.
A sample run looks like this:
! pip install transformers accelerate bitsandbytes --quiet
! git clone https://github.com/EleutherAI/lm-evaluation-harness
# I needed to comment out a `.to(self.device)` in gpt2.py
! cd lm-evaluation-harness && pip install -e . --quiet --upgrade
! cd lm-evaluation-harness && python main.py \
--model hf-causal \
--model_args pretrained=monsoon-nlp/mGPT-13B-quantized \
--tasks xcopa_id,xstory_cloze_id \
--batch_size 2 \
--device cuda:0It takes 5 minutes to download mGPT-13B-quantized to CoLab and put it on a V100, and 3+1/4 hours to evaluate Hindi on both. XCOPA is a lot smaller, so Indonesian goes faster. After seeing generated text from this model and being worried how to handle 8-bit (let the config.json handle it), I wish that I could've seen mid-run metrics to know whether it was working?
Anyway here are some zero-shot results (not looking so hot, but it's without fine-tuning, few-shot, or prompting).
| Task |Version|Metric|Value | |Stderr|
|---------------|------:|------|-----:|---|-----:|
|xnli_hi | 0|acc |0.4136|± |0.0070|
|xstory_cloze_hi| 0|acc |0.5486|± |0.0128|
|---------------|------:|------|-----:|---|-----:|
|xcopa_id | 0|acc |0.6280|± |0.0216|
|xstory_cloze_id| 0|acc |0.5837|± |0.0127|While looking for comps, I found Cahya Wirawan has been posting pretrained and finetuned Indonesian LLMs, including GPT2-large-indonesian-522M. The V100 can run a huge batch size through this model (add --batch_size auto to the eval command).
I decide to give both three examples for some practice.
About halfway through this process I considered whether XNLI tasks are a good example, as they were initially made for BERT / masked language models. The authors have a way of wording the prompts to help GPT / causal language models, but it's an odd fit.
gpt2 (small, no Indonesian specific training)
| Task |Version|Metric|Value | |Stderr|
|---------------|------:|------|-----:|---|-----:|
|xcopa_id | 0|acc |0.5120|± |0.0224|
|xstory_cloze_id| 0|acc |0.4553|± |0.0128|
mrm8488/bloom-7b1-8bit on A100 / batch size 32
| Task |Version|Metric|Value | |Stderr|
|---------------|------:|------|-----:|---|-----:|
|xcopa_id | 0|acc |0.5320|± |0.0223|
|xstory_cloze_id| 0|acc |0.4838|± |0.0129|
cahya/gpt2-large-indonesian-522M
| Task |Version|Metric|Value | |Stderr|
|---------------|------:|------|-----:|---|-----:|
|xcopa_id | 0|acc |0.5520|± |0.0223|
|xstory_cloze_id| 0|acc |0.4858|± |0.0129|
monsoon-nlp/mGPT-13B-quantized
| Task |Version|Metric|Value | |Stderr|
|---------------|------:|------|-----:|---|-----:|
|xcopa_id | 0|acc |0.6160|± |0.0218|
|xstory_cloze_id| 0|acc |0.5725|± |0.0127|Here's the final notebook: https://colab.research.google.com/drive/1ZcUbygUXUbEV3W6LQ_DNYkKeYIl7yr9z?usp=sharing
Future
The accuracy of both models unexpectedly slightly declined when given the three examples? And when I tried two examples, the gpt2-large-indonesian accuracy went up a little on the XCOPA task, but still underperformed on the second task. Conclusion: I should come up with a way to send in a better prompt and evaluation plan.
BLOOM should also be further tested, since they include Indonesian (paper says 1.2% of training corpus).
I'm hoping to share the quantized mGPT, get feedback, and see about doing LoRA / QLoRA finetuning before sending prompts into the evaluation.